
Authors: Louis Keryhuel & Khanh Nguyen Introduction In this post, we'll be discussing one of our...
As 2021 turned into 2022, Homa's Data team underwent a fundamental change. To adapt to scaling up (in data volume, stakeholders' expectations, and the number of people within the group), we decided to do a sizable refactor on our data pipelines. In this article, we'd like to share some of our decisions, their results after one year, and the lessons we've learned along the way.
Context
At the time, we were already using industry-standard infrastructure, including Redshift as the analytics database and Airflow with Kubernetes for orchestration.
However, some limitations in our codebase were starting to show:
- Inefficient repository structure
We had separate repositories for different pipelines, especially when other engineers wrote them. While multi-repo is a good strategy, we needed to implement it properly. We had many feature overlaps between these repositories, with standard features being reimplemented, sometimes in different ways. These were wasted efforts, and it took action for engineers to cross-contribute to others' projects because they had to take the time to learn how the other repo is written. Pipelines were hard to maintain, especially when their authors left the company. - ETL, Pandas, and S3
As a result of using dense-compute nodes, we had minimal storage in our Redshift cluster. We were forced to do heavy transformation and aggregation in Python Pandas before loading data into our warehouse to reduce volume. It was both slow and limiting. We would have to extract the data again when there's an error during transformation. We also sometimes chose to store data only on S3 and not Redshift, but without a structure that can be easily processed by data lake tools (AWS Athena or Redshift Spectrum). It was challenging and inconvenient for newly joined analysts to access the data they needed.
We wanted to correct these shortcomings while keeping the things that worked and minimizing the amount of work to make it happen.
Key changes
Removing database storage limit
The data warehouse architecture was still the most fitting for us. It meant putting our analytics database at the center of all our data operations. For this to be possible, we needed to remove the storage limit.
We considered moving to other MPP databases that decouple storage and compute by default (Snowflake, BigQuery, or the flashy lake-house architecture with Databricks). However, such a change would require much effort, which we would rather avoid. Luckily, with the introduction of Redshift’s RA3 node, we could achieve this decoupling simply by changing our cluster configuration in a few clicks. We had to trade some computing power to get the extra storage, but it was well worth it.
ELT
A lot has been written about ETL vs. ELT. For us, it was an obvious choice to keep extraction dumb, to load data immediately to the warehouse, and to put all transformations inside the database using SQL. It makes transformation faster, more convenient, and more approachable for analysts. When we discover a data error, detecting whether it comes from the source system itself or our transformation logic is straightforward.
Data Modeling Principles
To help keep our data warehouse organized, logical, and thus easy to use, we have formalized a list of rules on how the data should be designed. For example:
![]()
-1.png?width=875&height=566&name=Untitled%20(3)-1.png)
.png?width=787&height=324&name=Untitled%20(4).png)
Mono-repo
We decided against the multi-repo structure because we envision that, in the foreseeable future, we will have only 5-10 people actively working on these data pipelines and related projects, all of which benefit from each other. We don't require the scalability that multi-repo provides and are unwilling to tolerate its difficulties. Here's a rough structure of our repo:
.
├── data_global (repo name)
│ ├── adhoc_analyses (mainly jupyter notebooks from the analyst team)
│ ├── data_raw (Python code for data extraction, populating data in Raw layer - see our data modeling principles above)
│ ├── data_integration (mainly dbt models, populating data in Integration layer - see our data modeling principles above)
│ ├── data_presentation (mainly dbt models, populating data in Presentation layer - see our data modeling principles above)
│ └── utils (both reusable Python helpers and dbt macros)
├── scripts (thin wrapper to expose our Python code as cli programs)
├── tests (both Python unit tests and dbt data tests)
└── dbt_project.yml
To assist new joiners in setting up their environment and running the code as quickly as possible, we also include an easy way to retrieve the necessary secrets from secure storage and default config files for the most used IDE in our team (VS Code). It should take only a few minutes from cloning the repo to being able to run their first application locally.
Extract-Load with DataFetcher
We have dozens of sources and more than a hundred reports to extract data. Therefore, we inevitably need a common framework to facilitate this process, allowing us to write configs instead of repeating boilerplate code.
Many commercial and open-source solutions already do this (a few names come to mind, such as Fivetran, Stitch, Airbytes, Singer, etc.). However, we've decided to write our framework because:
- We want to make the most use of our legacy code.
- Many sources we use are not too popular and need an off-the-shelf connector already written. We would have to register many custom connectors either way.
- We want to keep this flexible and fit precisely to our needs.
Regardless, we learned a few ideas from those open-source projects and applied them in our decision-making.
- Object-oriented vs. functional programming OOP was chosen because it is more suited for tasks holding mutable data objects and executing logic in specific orders - "many things with few operations.”
- Favor composition but still make use of inheritance where fit
The design of our DataFetcher framework can be illustrated as follows:
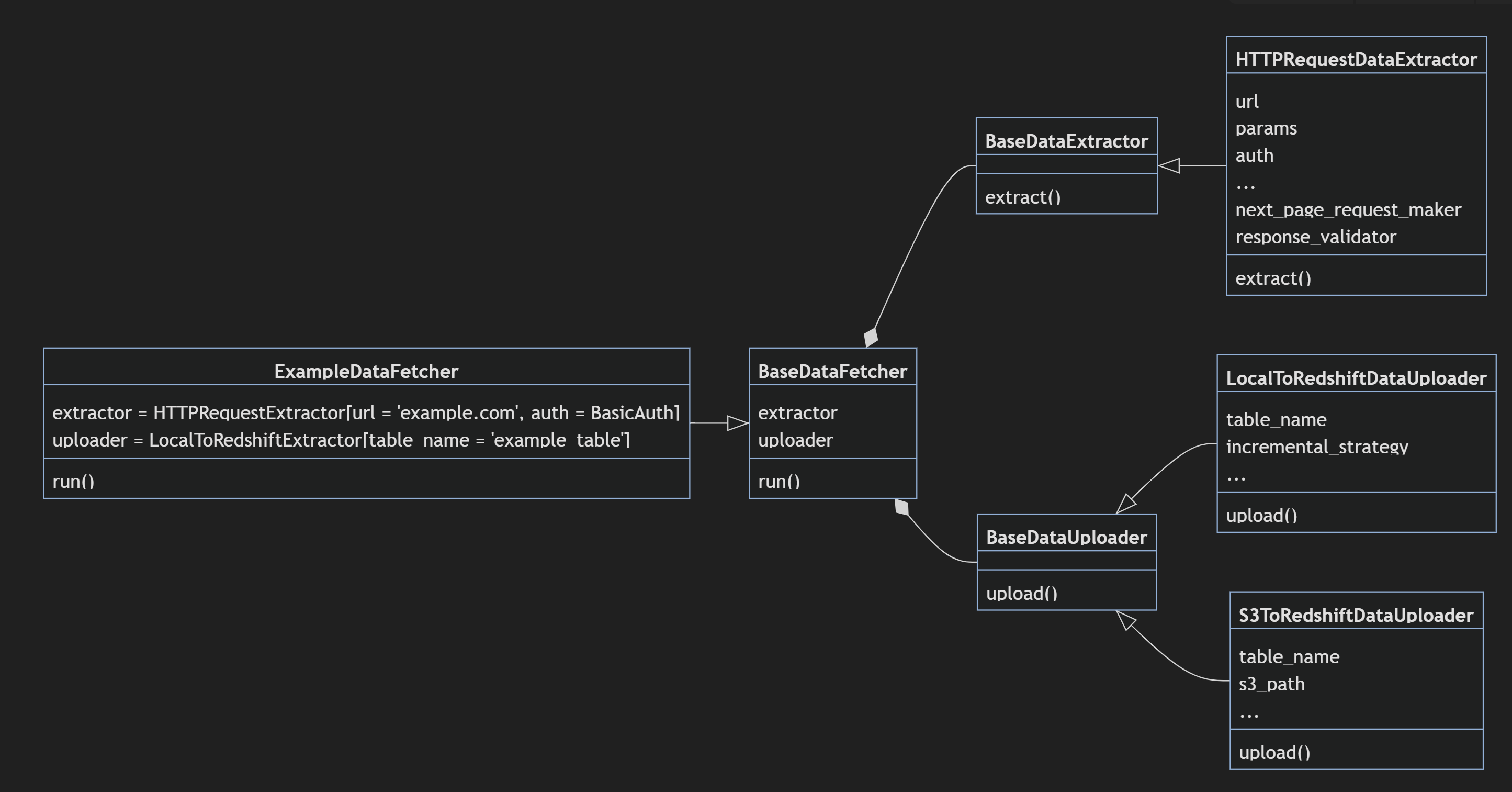
Every "report" (a specific type of data that comes from a single endpoint and can be loaded into one database table) is handled by a concrete DataFetcher class. Inside this class, a concrete DataExtractor and DataUploader are defined and composed with the fetcher object. They specify how to retrieve and ingest the data into our database. The DataFetcher class inherits from BaseDataFetcher, which handles instantiation and coordination of the extractor/uploader and performs tasks such as calculating the dates to run, retrying, error handling, etc.
In detail, a concrete DataFetcher would look something like this:
class ironSourceAppsDataFetcher(BaseDataFetcher):
"""
Extract and load ironSource Apps data.
<https://developers.is.com/ironsource-mobile/air/application-api/>
"""
default_backfill_periods = 3
extractor = HTTPRequestsDataExtractor(
url="<https://platform.ironsrc.com/partners/publisher/applications/v6>",
auth=HeadersAuth(auth_headers_callable=get_auth_header),
response_parser=[JsonResponseParser()],
)
uploader = LocalToRedshiftDataUploader(
table_name="raw_ironsource_apps",
incremental_strategy = "overwrite",
)
While anyone can write a custom extractor for their use case, most of our data sources can be extracted using the standard classes, such as the HTTPRequestsDataExtractor in the above example. We have made these classes fully featured and flexible enough to adapt to most scenarios. We also have other standard extractors such as S3DataExtractor, GoogleSheetsDataExtractor, etc. So, in the future, whenever we see ourselves repeating the same code, we can quickly turn that into a standard extractor to be used in similar cases.
Transformation with dbt
At the time of our refactoring, dbt has become mainstream. So it was a no-brainer for us to make dbt the central framework for managing our data warehouse pipelines. Not only is it a great tool that adds real value, but there is also a growing number of tools, especially in data quality, catalog, and observability, that support easy integration with dbt-backed warehouses.
-
Project structure and data model
As mentioned above, we put the dbt code in the same repo with everything else in our pipelines. We organized the repo according to our data model rather than using the default structure suggested by dbt. It requires a little tweak in our dbt_project.yml config and complicates things when they add support for the Python model. But overall, it's well worth it for us to customize this structure as it makes navigating our code much more intuitive.
In the "Data Modeling Principles" section, we've briefly mentioned the different layers in our data structure. To put it in more detail:
.png?width=780&height=559&name=Untitled%20(5).png)
(You might find this similar to Databricks' Medallion Architecture. It is just a happy coincidence. Similar ideas around the community probably inspired us at the time.) We still need to fully apply an established data modeling methodology (Entity-Relation, Kimball, Inmon, Vault, etc.). So instead, we curated ideas from all of them into a hybrid method that makes the most sense for us. This allowed us to be fast and flexible but still able to follow good practices.
-
Trigger and Orchestration
Even with dbt, we still want to centralize all pipeline execution under our existing Airflow service. Therefore, the dbt commands are packaged as an Airflow task to be run inside Kubernetes pods. We have written some light wrapper code to make creating dbt tasks as easy as possible:
task_a = dbtTaskConfig(node="dim_currency_exchange", type="model")
task_b = dbtTaskConfig(node="dim_countries", type="seed+test")We prefer running only one model/seed per Airflow task as it makes for more convenient monitoring. However, we do have to manually set the task dependency (rather than using dbt’s automated lineage).
-
Incremental models
Due to the large volume of data we have to handle, most of our models are incremental. To aid engineers in correctly implementing incremental models, we have a written guideline containing several different strategies. Here, we will share our most commonly used approach:
Dynamic incremental using
dt_last_updated-- This is an example for a dbt model that combines data from 2 large tables - raw_1 and raw_2.
-- If you need 1, 3 or more raw tables, the logic remains the same.
-- Note the unique_key being d_date.
WITH
-- Specifying the period that contains the new updated data (new since last run)
dates_with_new_data__from_raw_1 AS
(SELECT
MIN(d_date) AS min_date
FROM
WHERE TRUE
)
,dates_with_new_data__from_raw_2 AS
(SELECT
MIN(d_date) AS min_date
FROM
WHERE TRUE
)
,dates_with_new_data AS
(SELECT
LEAST(r1.min_date, r2.min_date) AS min_date
FROM dates_with_new_data__from_raw_1 AS r1
CROSS JOIN dates_with_new_data__from_raw_2 AS r2)
-- Selecting the data and building the model
,raw_1 AS
(SELECT
d_date,
...,
dt_last_updated AS dt_source_data_last_updated
-- This field is needed so that at next run we know which data from the raw table has already been processed and thus can be skipped
FROM
WHERE d_date >= (SELECT min_date FROM dates_with_new_data))
,raw_2 AS
(SELECT
d_date,
...,
MAX(dt_last_updated) AS dt_source_data_last_updated
-- If you need to use GROUP BY to transform data, the appropriate function to apply to this field is MAX()
FROM
WHERE d_date >= (SELECT min_date FROM dates_with_new_data)
GROUP BY d_date, ...)
SELECT
d_date,
...,
LEAST(raw_1.dt_source_data_last_updated, raw_2.dt_source_data_last_updated) AS dt_source_data_last_updated
FROM raw_1
JOIN raw_2 USING(d_date, ...)
With this approach, every time the model runs, it will process all the newly-updated data rows from the source table (the rows that have a higher dt_last_updated than the recorded time from the last run).
This is currently the preferred option because of the following advantages:
- Data is better synchronized with the source table's updates, with very little need for backfill and retrospective fixes.
- No redundant data processing (compared to the other approach mentioned later).
Important notes when using this approach:
- The code above only works with
delete+insertincremental strategy (which is the default and only strategy available for Redshift at the moment). - In the example above, we used
d_dateas theunique_key. But there's nothing stopping you from using other fields if you know what you're doing. - If you're joining with a dim table that doesn't have
dt_last_updated, or if your model logic changes, the changes won't be included in incremental runs. A full_refresh will be required.- Or, if you know you only need to backfill those changes for a certain period, manually run a query that deletes all rows from the start date you want until the latest date => the subsequent incremental run will reprocess all the data that has been deleted. But it goes without saying that this type of manual intervention should be avoided in most cases.
-
Testing
We care enormously about data quality and write useful tests on all our essential models. The tests are also triggered through Airflow and will send an alert to our Slack when it fails, depending on the severity and importance of the test. We also link top critical tests with particular actions, such as direct notification to business users or pausing some user-facing data products from refreshing and taking in the bad data.
-
Documentation
We write documentation for our models when we can, especially when there are intricacies that users must know before using this model. For now, the docs are hosted on dbtCloud with a free account.
Outcome
All the changes above took significant effort. But after those efforts were paid, we ended up in a much better state than when we started. The biggest benefits we've seen include:
- The precise data source of truth thanks to the mono-repo, which reduces overlaps between projects, and the consistent data model, which prevents multiple versions of identical/similar metrics.
- Easy change propagation when we modify the input sources (when we have to adapt to new changes in our data sources, usually we only have to modify a small upstream model and the correct data will propagate down).
In conclusion, the Homa data team's refactoring and re-data-warehousing efforts have been successful in addressing the limitations in our previous codebase. By removing the storage limit on their data warehouse and moving to an ELT process, we have made transformations faster and more convenient for analysts. Formalizing a list of data modeling rules and implementing a mono-repo structure has also helped to keep our data warehouse organized and easy to use. Additionally, providing an easy setup process for new team members has improved onboarding and productivity. Overall, the changes made have allowed the team to adapt to an increase in data volume and stakeholders' expectations while minimizing effort and maximizing efficiency.
By sharing this, we aim to give you more valuable ideas you can apply to your work.
If you want to learn more about open positions at Homa, consult this page.